
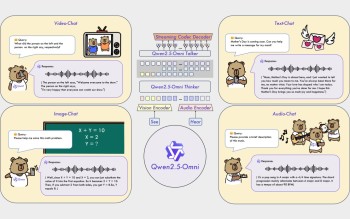
阿里云发布了一款名为通义千问Qwen2.5-Omni-7B的全能AI助手模型,并宣布该模型正式开源。该模型是阿里云通义系列中的首个端到端全模态大模型,能够处理文本、图像、音频和视频等多种输入,实时进行多模态任务。这款模型极大地丰富了阿里云的模型服务平台,为用户提供了更多选择。
阿里云通义千问Qwen2.5-Omni-7B模型介绍
根据东方日报报道,阿里云宣布通义千问Qwen2.5-Omni-7B正式开源。这款模型是全模态的大型模型,能够实现端到端的处理,非常适用于智能语音应用领域。通过该模型,用户可以实时进行多模态输入数据的处理和分析,为用户提供定制化的AI助手服务。
通义系列模型服务平台百炼
根据阿里云文档,百炼是阿里云的大模型服务平台,提供了丰富多样的模型选择,包括通义系列大模型和第三方大模型,涵盖了文本、图像、音频、视频等不同模态。用户可以根据自己的需求选择合适的模型进行应用,实现个性化的AI应用场景。
通义千问大语言模型介绍
阿里云文档介绍了通义千问是阿里云自主研发的大模型,能够理解和分析用户输入的自然语言,以及图片、音频、视频等多模态数据。该模型可以应用于不同领域和任务,为用户提供多样化的服务和帮助。
通义千问-7B-Chat模型
ModelScope网站介绍了通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列中参数规模达到70亿的模型。Qwen-7B基于Transformer构建的大语言模型,在超大规模的预训练数据上进行训练,具有较强的处理能力。
快速实现LLaMA-7B指令微调
阿里云文档提供了在阿里云ECS上进行LLaMA-7B模型指令微调的训练方案。通过Alpaca提供的方法,用户可以实现性能更贴近具体使用场景的语言模型。
EAS一键部署通义千问模型
阿里云文档介绍了如何通过EAS一键部署通义千问-7B(Qwen-7B)模型。用户可以快速部署这一70亿参数规模的模型,基于Transformer构建的大语言模型,应用于各种场景中。
中国大模型开源项目
GitHub上的awesome-LLMs-In-China项目中列出了中国大模型的相关信息,包括开源的小模型baichuan-7B和Baichuan-13B,以及阿里云通义千问等模型。这些开源模型为中国的大模型行业发展做出了重要贡献。
国产“小模型”的开源之路
上观网报道了国内AI开发者社区“魔搭”(ModelScope)上架了两款开源模型Qwen-7B和Qwen-7B-Chat,分别为阿里云通义千问的70亿参数通用模型和对话模型。这两款模型的开源将推动“百模大战”的发展,为中国AI产业的进步注入新的动力。
以上是对阿里云通义千问Qwen2.5-Omni-7B模型及相关开源模型的详细分析和报道。
来源:



